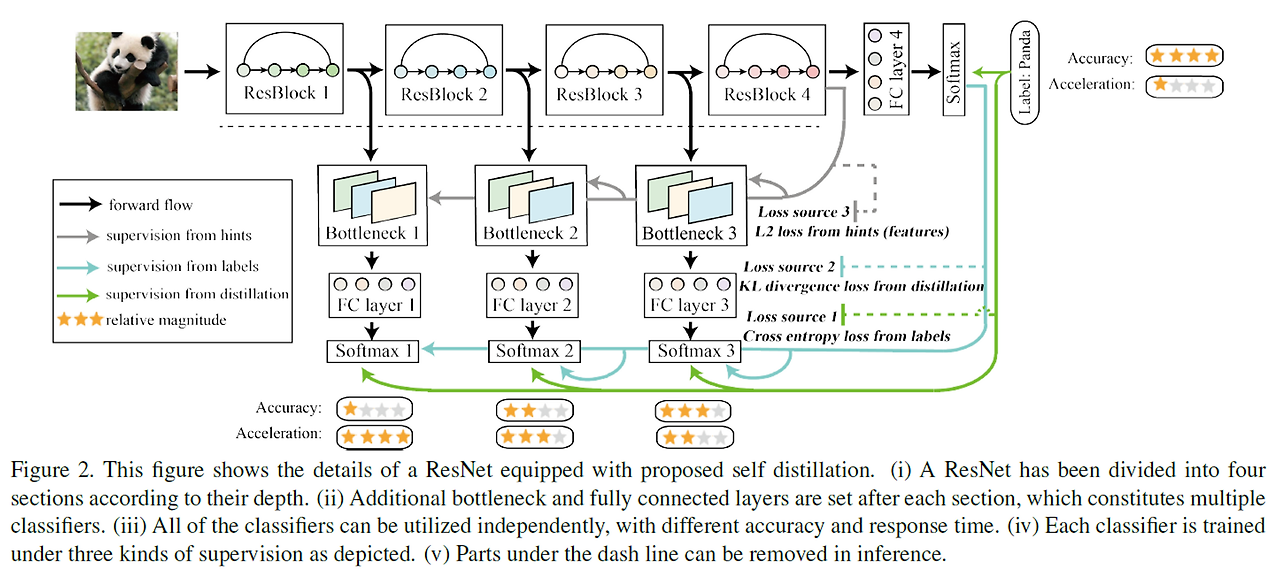
Before the StartKnowledge Distillation의 컨셉에 대해서 알고 있어야 편합니다0. AbstractAccuracy를 조금이라도 더 올리기 위해서 deeper, wider network를 설계하는게 하나의 트렌드였다구조를 키워서 정확도는 올라갔지만, Computational cost가 높아졌다. Self KD는 구조를 줄이면서 성능은 올렸다. 아이디어는 하나의 모델을 여러 section으로 나눠, deeper section에서 shallow section으로 distillation을 적용해주는 것이다.1. Introduction최근 나온 구조들은 cost가 굉장히 크고, 이전에 비해 acc를 올리기 위해 필요한 cost의 증가량이 커졌다. (ex. 이전에는 1% 올리기 위해 5G..