0. 왜 골랐는가
Open Review에서 굉장히 좋게 평가해주었길래 어떤 아이디어가 그렇게 참신한가 싶어서 골랐다.
1. Multi Task Learning이 낯선 사람들을 위해
1.1. 간단한 소개
멀티 태스크 러닝(이하 MTL)은 이름에서 알 수 있듯이, 하나의 모델이 여러 task를 수행해준다. 하나의 모델이 여러 task를 동시에 수행하기 위해서, 구조를 공유하거나, parameter를 유사하게 만들어준다. 아래는 동일한 parameter를 공유하는 “Hard Parameter Sharing”, 그리고 동일하지는 않지만, 유사한 parameter를 사용하는 “Soft Parameter Sharing”의 예시이다.

Fig1. Hard Parameter Sharing과 Soft Parameter Sharing에 대한 모식도
Soft Parameter Sharing의 경우는 결국 서로 다른 Parameter를 사용하기 때문에 Memory Efficient한지는 의문이다.
- Soft Parameter Sharing은 어떻게 Parameter를 유사하게 하는가?
- 아의 수식처럼, Loss function에서 Regularization term을 넣어서 Parameter 간 차이가 크지 않도록 한다.
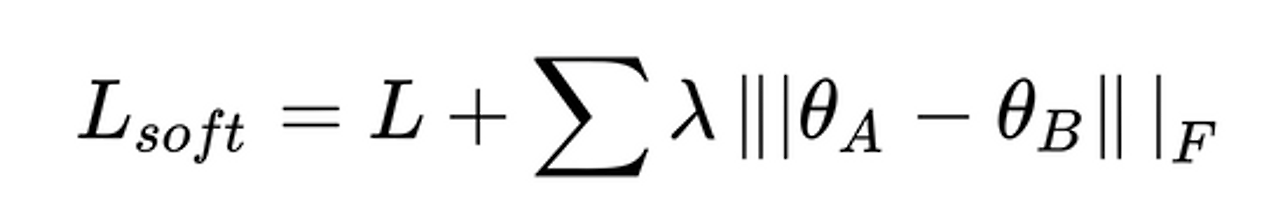
MTL의 예시로는 흔히들 자율주행을 많이 들고는 한다. 하나의 장면에서, object detection이나, edge detection 등을 다양한 task를 한 번에 수행해야하기 때문에 자율 주행에 이를 적용할 수 있다.

물론 여러 모델을 동시에 돌린다면, 동일한 결과를 얻을 수 있겠지만, 여러 모델을 Parallel하게 돌릴 수 있는 Computing Resource가 있거나, Sequential하게 돌리려면 그 만큼 시간이 소요될 것이다.
1.2. 사기는 아닌가
각 Task마다 최적의 Parameter가 있을 것이라는 건 자명한데, 여러 가지 Task를 같이 학습하는 건 Performance 측면에서 굉장히 안좋은게 아닐까? 라는 생각을 할 수 있다.
실제로 여러 개의 Single Task Learning을 동시에 진행하는 것이 더 좋은 Performance를 보여줬다. 하지만, [1]에서는 Fixed Resource인 상황을 가정하여, n-task일 때, Single Task Learning에 1/n만큼의 Resource를 부여해서 실험했다.
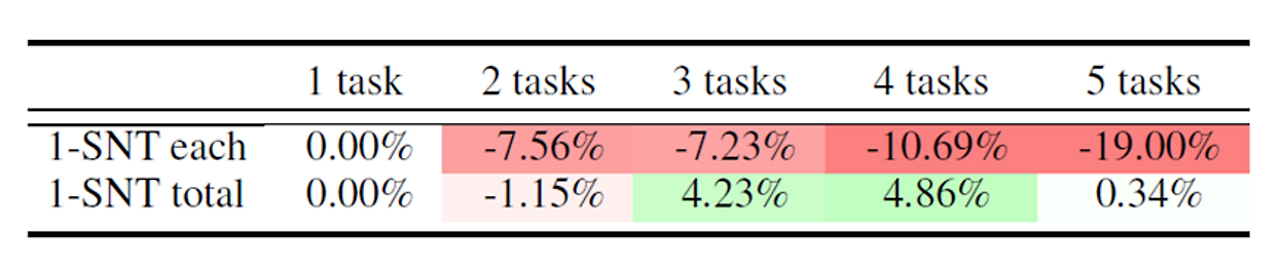
결과적으로는 Fixed Memory 상황에서 여러 가지의 Task를 수행해야 한다면, MTL은 좋은 선택이 될 수 있다는 것을 보여준다.
1. Introduction
1.1. 당시 MTL의 연구 방향[2]
조금 오래된 Survey논문이라 현재의 동향과는 동떨어져 있을 수 있지만, 당시에는 크게 MTL의 연구 방향은 3가지로 나뉘어져 있다고 한다. ( 또 다른 분류 방식도 있으나, 이번 논문과는 관계가 없기 때문에 나중에 다루도록 한다. )

- Architecture ( Fig 5 )
- MTL을 더 잘 수행할 수 있는 Architecture 자체를 연구하는 방향
- Optimization ( Fig 6)
여러 Task들이 더 잘 최적화될 수 있도록 도와주는 방법론에 대한 연구가 이뤄졌었다. 여러 Task에 대해 학습 속도가 일정하지 않으면, 한 Task가 충분히 학습되지 않은 상태에서 다른 Task가 최적점에 도달하는 문제가 발생한다. - Grouping Method ( Fig 7)
마지막으로 Task들을 어떻게 분배하는지에 대해서 연구하는 방향이다. Grouping에 대한 연구가 당시 가장 희소했다고 한다.

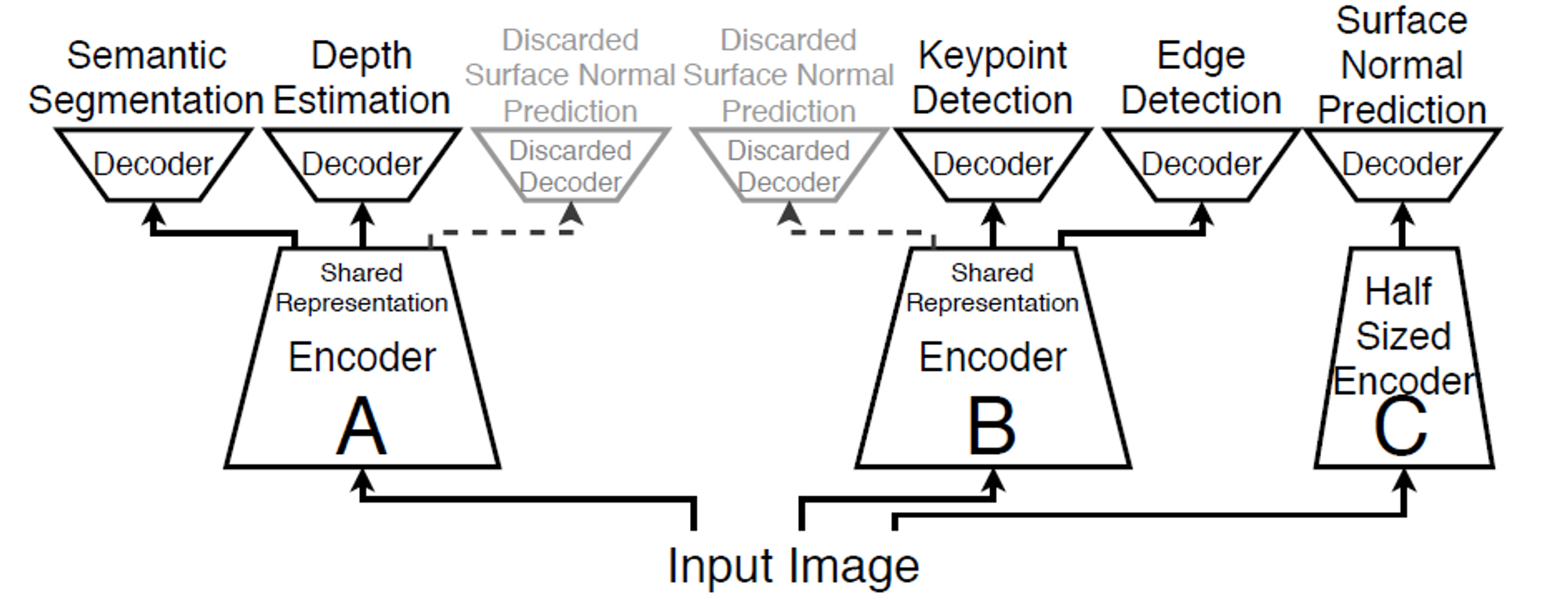
1.2. 왜 Grouping이 중요한가?
1.2.1. Negative Transfer
Fig7.에서 알 수 있듯, 하나의 Group은 Encoder를 공유한다. 만약 Group내의 여러 Task의 Loss가 서로를 방해하는 방향으로 최적화된다면, 아무리 최적화를 잘한다고 하더라도, Loss의 하한선이 존재할 것이다.

1.2.2. Undeveloped Fields
논문이 나올 당시, Grouping 분야의 연구가 많이 진행되지 않았었다. Brute Force를 막 벗어난 정도였고, 대부분의 MTL Grouping은 Heuristic하게 이뤄졌었다.
2. Prior Works
2.1. Brute Force
말 그대로 그냥 찾는거다.
2.2.Which Tasks Should Be Learned Together in Multi Task Learning?[1]
2.2.1. HOA(High Order Approximation)
Idea: Higher Order Set을 Lower Order Set으로 approximation한다.
더 자세히 설명하자면, 2 task로 묶어서 Loss를 측정한 다음, 평균값으로 해당 Task의 단일 Loss를 예측한다.
- Example (B,C)=(0.2,0.3) then, A=0.1+0.72=0.4,B=0.2,C=0.4
- Approximate (A,B,C)=(0.4,0.2,0.4)
- (C,A)=(0.5,0.7)
- (A,B)=(0.1,0.2)
이러한 방식의 Approximation은 각 Pair의 조합에서의 Loss만을 신경쓰기 때문에, 세 개 이상의 Task를 묶었을 때의 시너지는 무시하지만, 그래도 어느 정도 잘 예측한다고 한다.
2.2.2 ESA(Early Stopping Approximation)
간단하게, Fully Trained Netowrk와 20%의 데이터만 학습시킨 Network와 Validation Loss의 Pearson 계수가 굉장히 높게 나온다는 사실을 발견하고 이를 활용한 방법이다.
단순히, Brute Force처럼 모든 Combination을 20%의 데이터만 사용해서 학습시킨 후, 가장 좋게 나온 Combination을 사용하는 것이다.

2.3. Forward/Backward Selection
feature selection기법 중 forward/backward selection과 유사하게,
Empty Set에서부터 task를 하나씩 추가하거나, Entire Set에서부터 하나씩 task를 drop하는 방식으로도 측정을 하는데, 이 경우는 random하게 정하기 때문에 유의미한 결과를 얻으려면 반복이 필요하다.

3. Problem Definition
Task,Set;T=τ1,;…;,τn
A Group of K Multi Task Network M=m1,;…;,mk
가 있다. ( 즉, mi⊆T, ∪imi=T,mi∩mj=\empty;where;i≠j)
shared parameter: θs
task-specific parameter: θi;for;τi
만약 어떤 multi task group으로 나눴을 때 Task의 Performance를 P(τi|M)로 나타낸다면, 우리의 목적은 Mmax←argmaxM;ΣP(τi|M)을 구하는 것이다.
4. Idea - Grouping Tasks by Measuring Inter-Task Affinity

전체적인 Processs는 위와 같다. 하나의 네트워크에서 모든 Task를 훈련시키며 Inter Task Affinity를 계산하고, 이를 통해 Network를 고른다.
그리고 고른 Network를 기반으로 다시 학습시킨다.
4.1. Definition of Inter Task Affinity
Hard Parameter Sharning의 경우, Shared Network가 하나의 Shared Encoder 역할을 해준다.
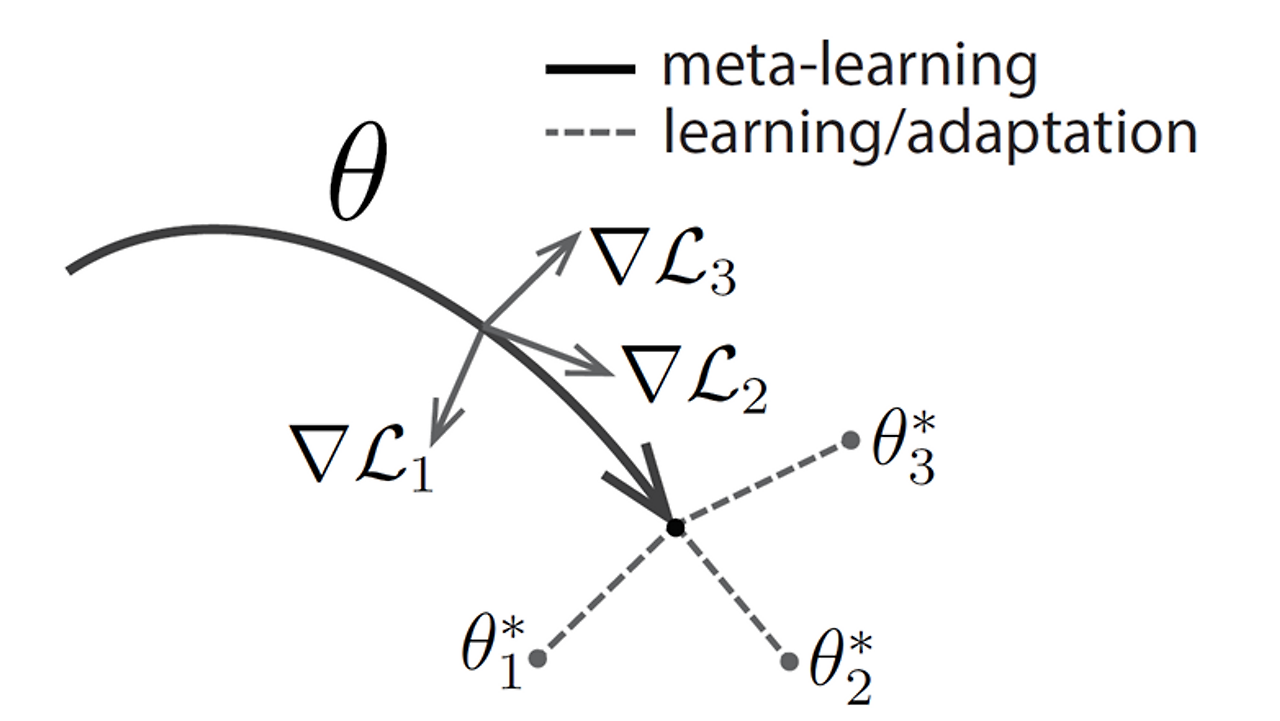
Ltotal=ΣLi에 대해 Gradient descent하는 과정에서, 각 task는 서로에게 영향을 주는데, 이 영향을 수치화시켜보고자 한 것이 이번 논문의 핵심 아이디어이다.
수치화시키기 위한 아이디어는 MAML[5]에서 가져오게 되었는데, 간단하게 설명하자면, 전체 Task Tτi의 Gradient로 업데이트한 파라미터를 이용해서 τj를 평가해서 수치화하는 것이다.

이 때, 수치화할 때, Loss에 대해 상대적인 scale이 있을 것이기 때문에 ratio로써 표기한다.

그리고 이를 training step에 대해 average한 수치로도 평가한다.

왜 Averaged Score가 필요한지는 Experiment에서 따로 설명한다.
4.2. Network Selection, TAG(Task Affinity Grouping)
한 번의 Training Step으로 Affinity Score Matrix를 얻을 수 있을 것이다.
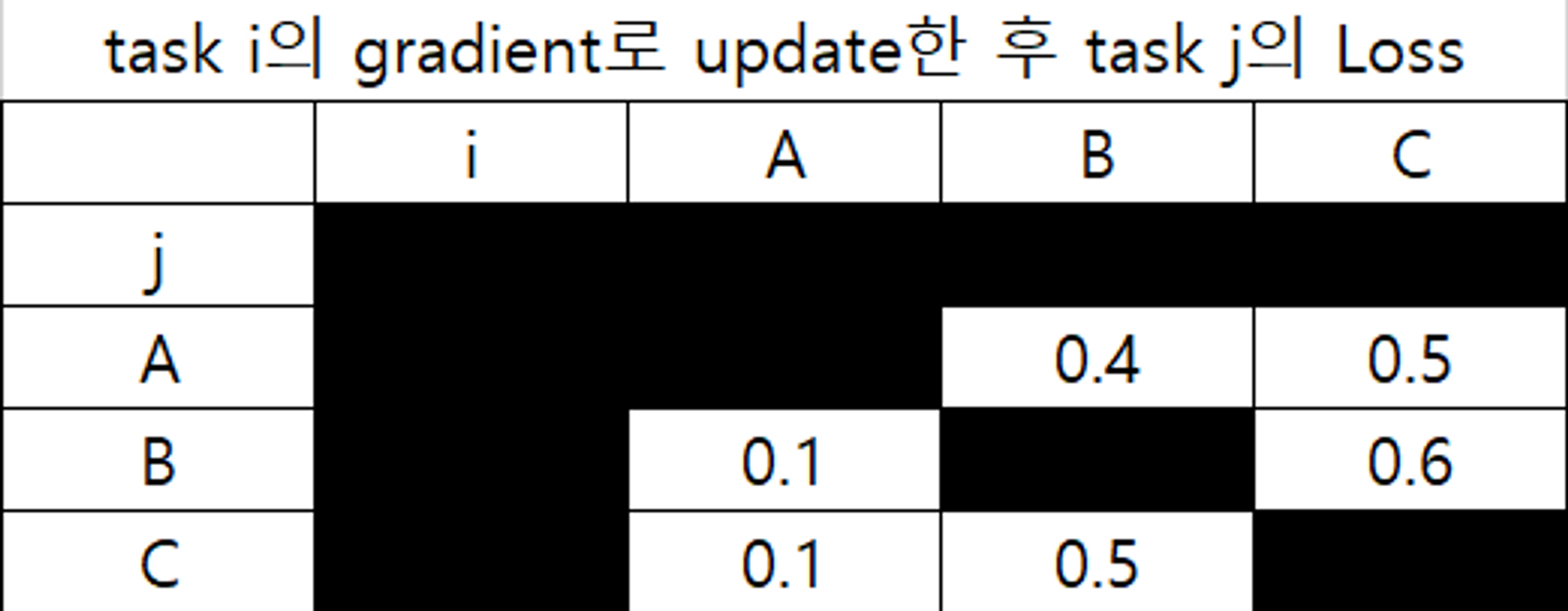
이렇게 얻은 Matrix에 대해서 앞서 언급했던 Inter Task Affinity가 최대가 되도록 grouping을 하면 된다. 이 문제는 Set Cover와 같이 NP HARD에 속하지만, Branch-and-Bound-like Algorithm(or Prune and Search)를 통해 해결할 수 있으며, task set에 대해 검색하는 것보다는 더 빠르게 할 수 있다.
Example 1.
만약 (A, B), C로 Grouping하게 되는 경우,

각 Group에서 Task가 받는 Affinity Score를 모두 합한다. 위의 경우는 A가 받는 영향은 0.4, B가 받는 영향은 0.1이다. C는 혼자 있기 때문에 영향을 안받으므로, Sum of Affinity Score는 0.5이다.
Example 2.

이 경우는 (A, B, C)의 경우로, A가 받는 Affinity Score는 B→A: 0.4, C→A: 0.5 이므로, average를 해서 0.45로 계산한다. 이와 비슷하게 B와 C는 0.35, 0.3으로 계산이 되며 total summation은 0.45+0.35+0.3=1.1이 된다.
이 example은 모든 element가 양수이기 때문에 다 같이 훈련시키는 경우가 좋지만, 일반적인 경우 Score가 음수가 될 수 있기 때문에 항상 같은 Group으로 두는 것이 이득은 아니다.
4.3. Theoritical Analysis
논문에서는 길게 적어놓았지만, 결국 이 Section에서 밝히고자 하는 것은
if;Zb→a>Zc→athen,La,b<La,c;? 이다.
즉, Affinity Score가 큰 것이 더 작은 Loss를 보증하냐는 질문인데,
La;be;α−strongly;convex,;β−strongly;smooth 라는 assumption이라는 가정 하에 증명할 수 있다.
자세한 증명은 논문에 있으나, 위의 가정 하에 Lemma1을 증명할 수 있고,
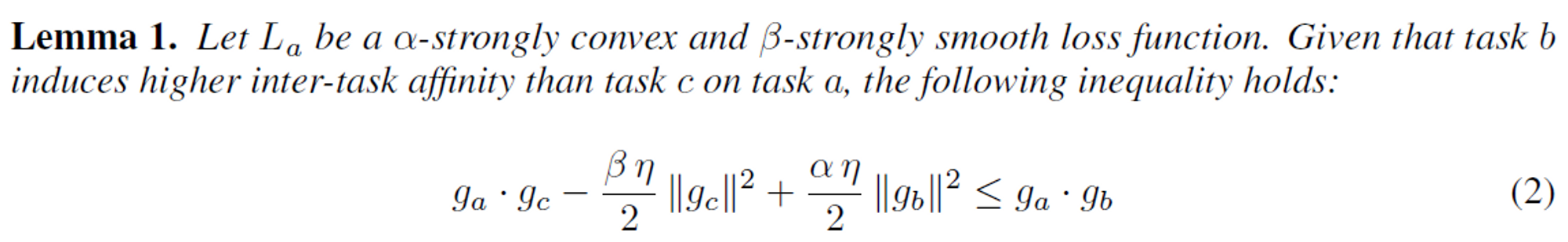
이 Lemma를 통해 명제1을 증명할 수 있는데

이 명제는 간단히 설명하자면,
if;Zb→a>Zc→athen,La,b<La,c;이 명제를 cos(ga,gc)에 대한 상한선이 있다는 가정하에 참임을 밝혀낸 것이다.
즉, (A, C) 대신 (A, B)를 Grouping할 때, A, C가 충분히 서로를 닮지 않아야 기대한 효과를 볼 수 있다는 말이다.
+) Cosine Similarity에 대한 조건은 Hessian number가 작을 때 mild한 조건이라고 한다.
5. Experiment
5.1. Before Experiment
각종 그래프에서 Notation들을 축약해서 사용해서, 한 번 정리하고 넘어가고자 한다.
- Grouping Methods:
- TAG: 이 논문에서 제안한 방법
- CS: Inter Task Affinity를 Gradient간의 Cosine Similarity로 측정한 경우
- RG: Random Grouping
- HOA: Prior Work 참조
- MTL: all tasks in single network
- STL: a network per task
- Optimization Methods: ( MTL에 optimization technique를 가한 결과)
- UW: Uncertainty Weight
- GN: GradNorm[4]
- PCGrad
그 외 디테일한 실험의 설정은 논문에서 찾아보도록 하자.
5.2. Supervised Task Grouping Evalutation
가장 먼저, Grouping을 찾는 시간에 대해 측정하고자 한다.

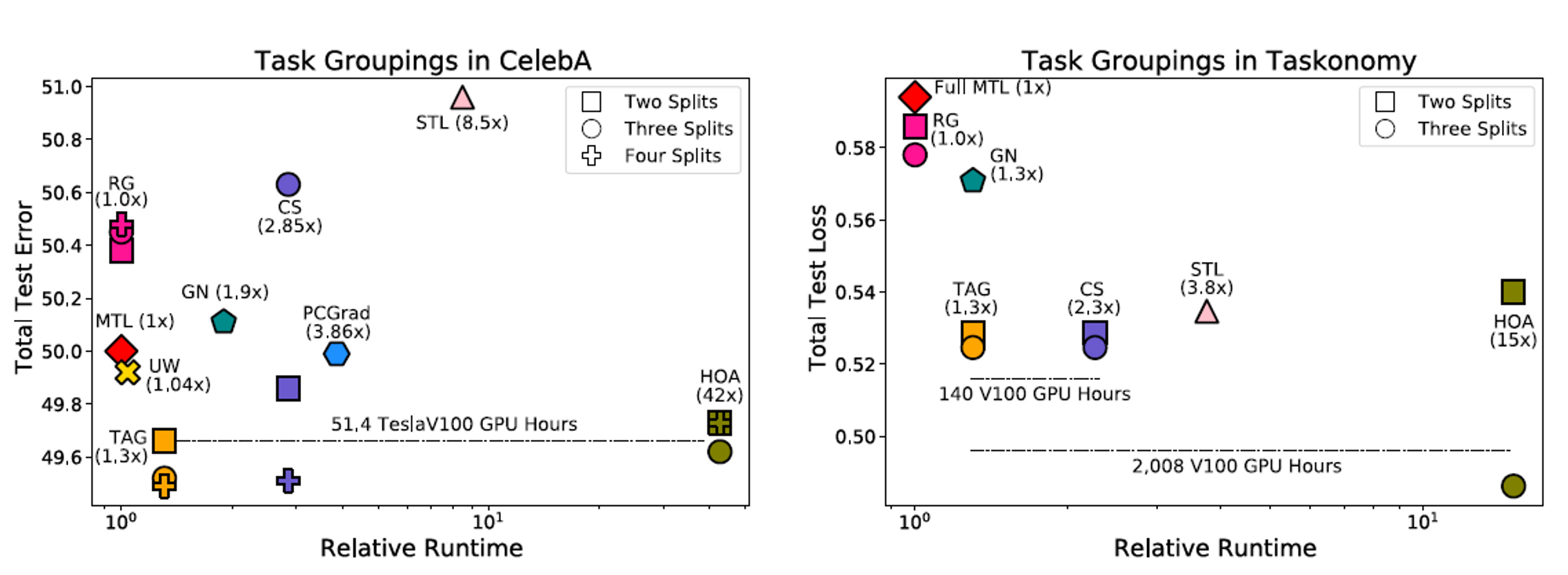
runtime과 test error 부분에서도 굉장히 준수한 성능을 낸 것을 알 수 있다.

- Latency Contraint, Memory Budget이렇게 부르는 이유는 Parallel하게 Network를 돌리게 되면, Latency는 각 네트워크의 파라미터에 비례할 것이며, Memory 자체는 전체 네트워크를 감당할 수 있어야 하기 때문이다.
- MTL은 네트워크의 크기가 커질수록 더 좋은 성능을 보여주는 경향이 있다. 따라서, 이를 비교하기 위해서, 각 Network의 크기를 Latency Contraint, 전체 네트워크의 크기를 Memory Budget이라고 하여, Parameter의 수로 이를 판단한다.
즉, 각 네트워크에 대한 파라미터 갯수에 대한 제한이 없는 경우, (대신 전체 네트워크의 크기에 대해서는 제한이 있는 경우)에는 GradNorm이나 다른 Optimization 방법보다 더 좋은 효과를 보여준다.
이는 Grouping 방법이, Optimization만큼이나 더 효율적으로 MTL의 성능을 향상시킬 수 있는 방법임을 보여준다.
5.3. Ablation Study
이 알고리즘을 CelebA Dataset에서 수행해, 총 5가지의 질문에 대해 대답할 수 있었다.
5.3.1. Affinity와 Loss는 Align되는가?
전체적으로 Affinity와 Loss가 잘 Align되는 것을 알 수 있으며, 이는 수치적으로 Pearson 계수로 체크해볼 수 있는데, 0.93으로 상당히 높게 나타난다.
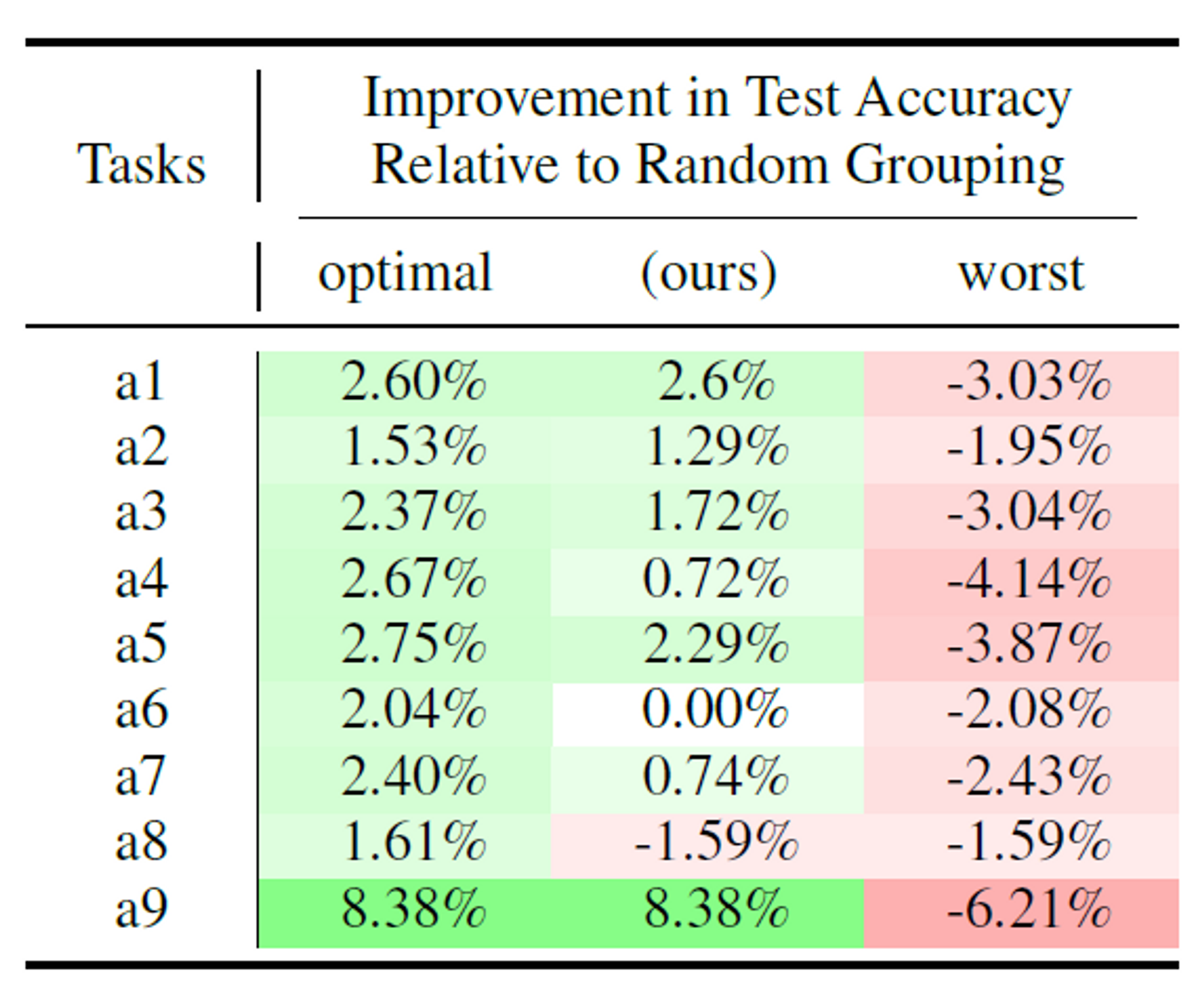
a8이 exception으로 나타나는데, 이는 theoritical analysis에서 나왔던 것처럼 inter task affinity의 차이가 크지 않은 경우이기에 이런 Limitation이 나타나게 되었다.
(a3의 best-worst affinity 차이가 0.16인데 반해, a8은 0.04라고 한다.)
5.3.2. Affinity는 매 Step마다 측정해야하는가?
every 10 step까지는 성능 저하 없이 작동하기 때문에 grouping speed를 늘릴 수 있다.
하지만, 그보다 더 큰 step size나, 초반/중반/후반에만 체크하는 것은 성능 저하를 일으킨다.
\

5.3.3. Affinity를 계산할 때, Training Set과 Validation Set을 이용하는 것 사이에 차이가 있는가?
두 값은 비슷하게 변화한다고 한다. Pearson 계수로 0.98이 넘는 값을 보여주며, Grouping 역시 동일한 결과가 나온다고 한다. validation set을 사용하는 것이 더 informative할 수 있으나, 큰 차이는 없으며, cost가 더 들기 때문에 training set을 사용하는게 더 좋을 것 같다.
5.3.4. Traning동안 Affinity는 어떤 양상으로 변하는가

- 특정하게 변하는 패턴은 없으나, 변하는 양상은 비슷하다.
- 초기 값은 유사한 경우가 많은데, 이 경우는 common representation vector에 대한 affinity를 배우기 때문이라고 해석했다.
5.3.5. Hyper-parameter가 변하면 TAG를 통한 Grouping도 바뀌나?
TAG의 Grouping이 Hyper parameter variant한지를 체크해보는 실험인데, batch size와 learning rate를 변화시킬 때, 가장 좋은 선택이 바뀌는 것을 체크했다.
total 511 possible combination 중에서 optimal grouping을 체크해서 relative performance를 체크했다고 하는데, 굳이 relative performance로 체크할 필요는 있었을까 싶다.

아무튼, hyper parameter에 따라서, 가장 좋은 option이 바뀌기 때문에, hyper parameter에 따라 TAG가 다르게 Grouping하는 것을 알 수 있다.
사실 마지막 실험의 경우는, 이 TAG가 hyper parameter에 대해서 variant하다는 별로 좋지 않아보이는 특성임에도 불구하고, 논문에 당당하게 적어놓은게 조금 신기했다.
Reference
[1] Trevor Standley et al., Which Tasks Should Be Learned Together in Multi-task Learning?, ICML 2020
[2] Yu Zhang et al., A Survey on Multi-Task Learning, IEEE 2017
[3] Ishan Misra et al., Cross-stitch Networks for Multi-task Learning, CVPR 2016
[4] Zhao Chen et al., GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks, ICML 2018
[5] Chelsea Finn et al., Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks, ICML 2017
마치며..
2023년도에 썼던 글을 블로그 이전하며 옮겨왔는데, 2025년의 시각에서 보는 논문과 이 때 읽으며 느낀 것들이 참 다르다고 생각된다. AI업계... 무진장 빠르다..
'AI' 카테고리의 다른 글
| [논문 읽기] Be Your Own Teacher - Improve the Performance of Convolutional Neural Networks via Self Distillation (0) | 2025.02.02 |
|---|