Before the Start
Knowledge Distillation의 컨셉에 대해서 알고 있어야 편합니다
0. Abstract
Accuracy를 조금이라도 더 올리기 위해서 deeper, wider network를 설계하는게 하나의 트렌드였다
구조를 키워서 정확도는 올라갔지만, Computational cost가 높아졌다. Self KD는 구조를 줄이면서 성능은 올렸다. 아이디어는 하나의 모델을 여러 section으로 나눠, deeper section에서 shallow section으로 distillation을 적용해주는 것이다.
1. Introduction
최근 나온 구조들은 cost가 굉장히 크고, 이전에 비해 acc를 올리기 위해 필요한 cost의 증가량이 커졌다. (ex. 이전에는 1% 올리기 위해 5GFLOPS가 필요하다고 했을때, 지금은 10GFLOPS가 필요하다. 단순 예시입니다.)
그래서 최근에는 경량화 기술이 많이 나왔는데, 대표적으로 pruning, quantization, Knowledge Distillation(이하 KD)이 있다.
KD는 teacher, student model이 따로 있어서, student model로 하여금 teacher model을 approximation하게 한다. 놀랍게도 student가 teacher보다 좋은 성능을 내는 경우도 있다고 한다.
1.1. Problem of KD
하지만 KD에도 몇 가지 문제가 있는데,
- low efficiency: knowledge transfer과정에서, student가 teacher을 뛰어넘는 경우는 드물다.
- design problem: teacher와 student를 design하기 어렵다. 특히, 어떤 student 모델에 대해 좋은 성능을 보여주는 teacher model을 디자인하는 것은 pretrain을 시키고, 검증해야하기 때문에 오래 걸린다.
1.2. Merits of Self KD
- 간단한 학습 step:self KD: one step ( 스스로 학습하면서 distillation을 주기 때문에)
- 기존 KD: pretraining teacher → knowledge transfer to student
- faster training time
- student model이 스스로 teacher 역할도 하기 때문에 더 빠르게 학습이 가능하다.
- Accuracy
- 더 정확하다고 하다. ( traditional KD에 비해서 )
2. Related Works
2.1. KD
모델 경량화에 주로 쓰이는 기법으로, Teacher Model과 Student Model을 두어서, Teacher Model의 판단을 가르치는 방식이다.
2.2. Adaptive Computation
Dropout과 유사하게, 특정 계산을 건너뛰는 방식이다.
1) layer 자체를 건너뛰거나, 2) feature map의 몇몇 channel을 스킵할 수도 있으며, 3) 혹은 pixel단위로 스킵하는 연구가 있다고 한다.
2.3. Deep Supervision
Gradient Vanishing 문제를 해결하기 위한 것으로, 내 기억으로는 GoogleNet인가에서도 비슷한 테크닉을 썼던 것 같다.
Deep supervision은 layer 중간중간에 supervision을 넣어주는 방식으로 Gradient Vanishing을 예방한다. Supervision을 넣어준다는 건, 중간중간마다 Loss를 계산하고 Back-Prop을 진행해준다는 소리다.(사실 이건 더 specific한 방법이고, supervision을 넣어주는 다른 방법도 있을 것이다.)
3. Self Distillation
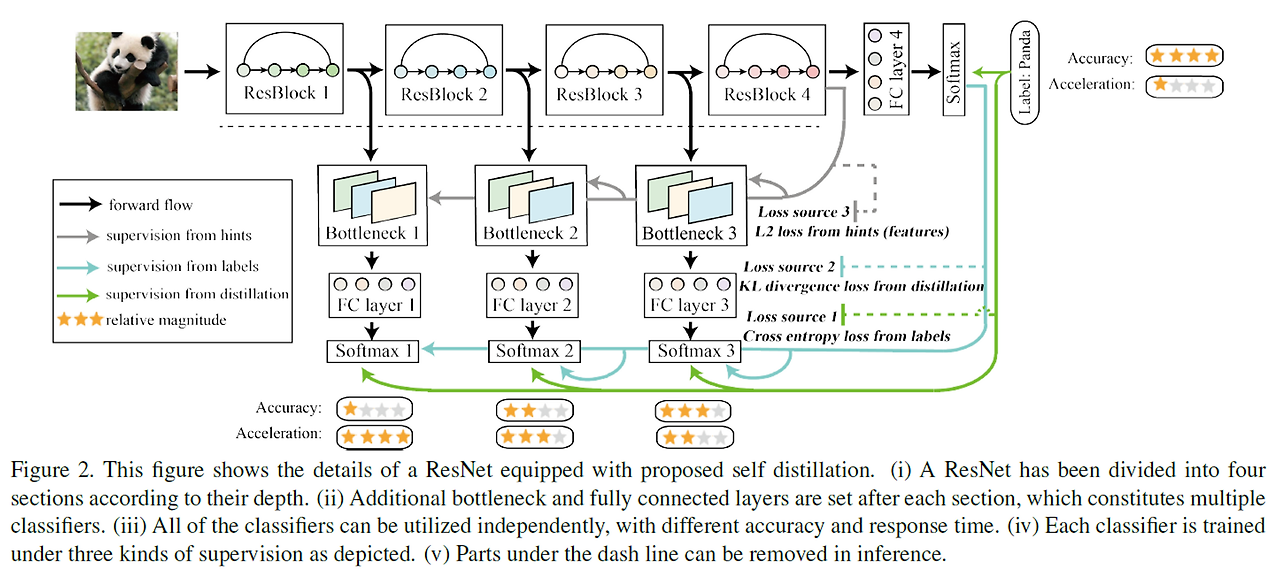
위의 사진에 모든 것이 들어있다…
먼저 모델을 section으로 나눠서, 그 사이마다 Classifier(Bottleneck + FC layer + softmax)를 둔다.
그리고 Deepest Classifier가 shallow classifier에 guidance를 주는 형식이다.
이 때, loss의 source는 총 3 곳이 있다.
- from Label ( Green Line )이 때, CE는 각각의 classifier가 얻은 output에 대해 계산한다.
- label 정보를 사용해서 얻은 Cross Entropy를 얻고, 이를 loss로 활용한다.
- from distillation ( BLue Line )
- Deepest Classifier가 얻은 softmax 값과 다른 classifier가 얻은 softmax value를 KL-divergence로 유사한 분포가 되게끔 한다.
- from hints ( Gray Line )
- Deepest Classifier가 사용하는 feature map과 shallow classifier가 사용하는 feature map 사이의 L2 loss를 사용한다.
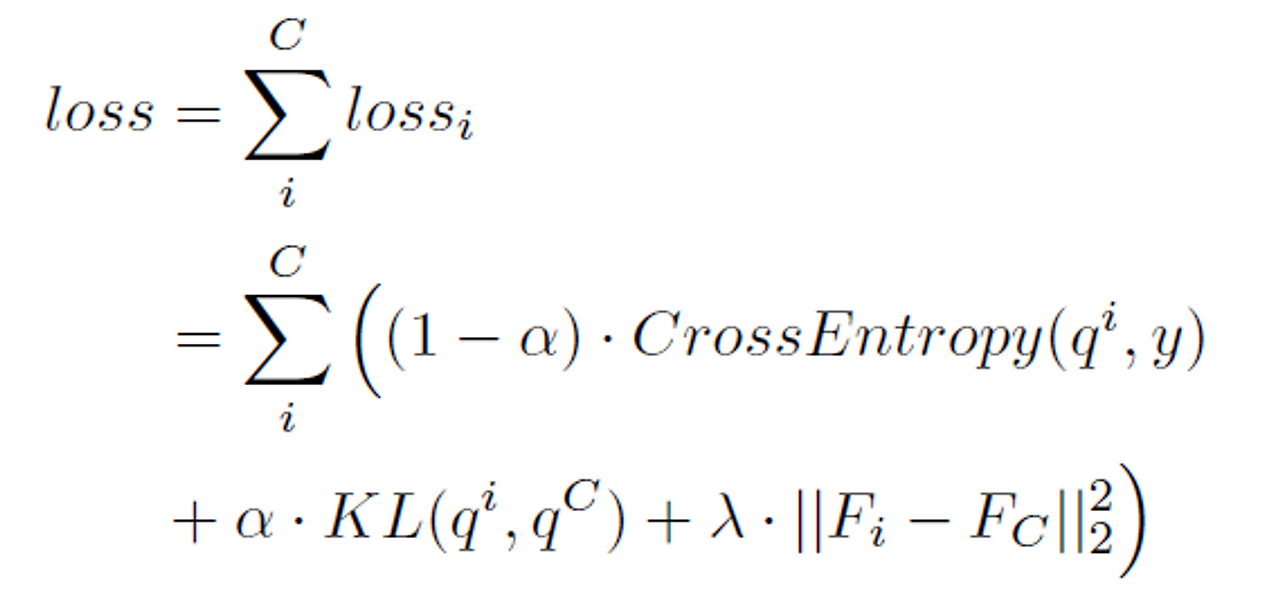
결론적인 loss는 위와 같고, α는 distillation ratio라고 할 수 있고, λ는 L2 loss를 위한 ratio라고 볼 수 있다.
4. Experiment
Skip! (아직 내가 디테일한 Setting까지는 필요하지 않다..)
5. Discussion and Future Works
Experiment로부터 얻은 결론(혹은 statement)가 세 가지 있다.
5.1. Self distillation can help models converge to flat minima which features in generalization inherently
한줄요약) sharp minima보다 flat minima에 converge하는 경향이 있다.
그렇다면 이게 왜 좋은 특성인가?
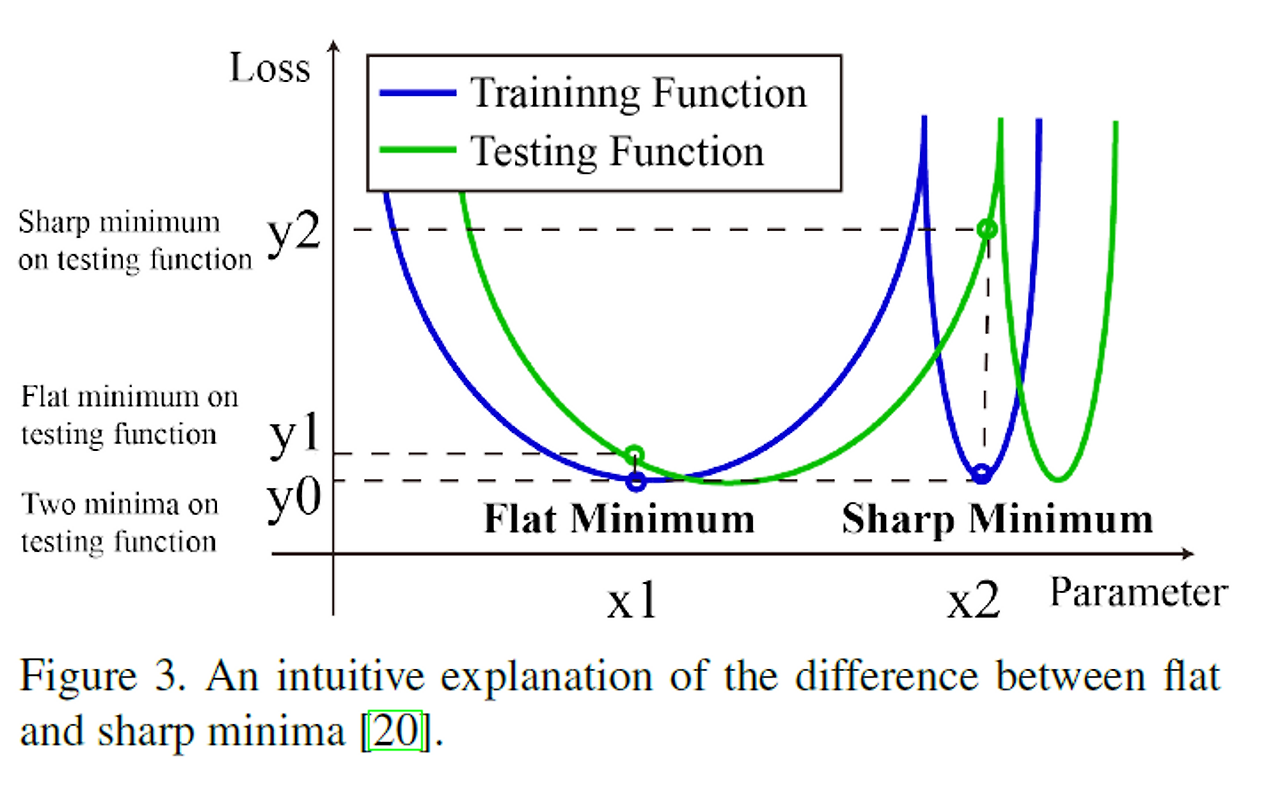
위와 같은 Training function이 있고, training function을 사용해서 test function을 estimate했다고 하자. sharp minima인 경우, 최적의 파라미터에서 조금만 bias가 생기면 loss가 크게 늘어난다.
하지만 flat minima인 경우에는 조금 bias가 생기더라도, 여전히 loss가 작게 유지된다. 즉 stable한 training이 가능해진다는 의미이다.
이걸 어떻게 증명했냐?
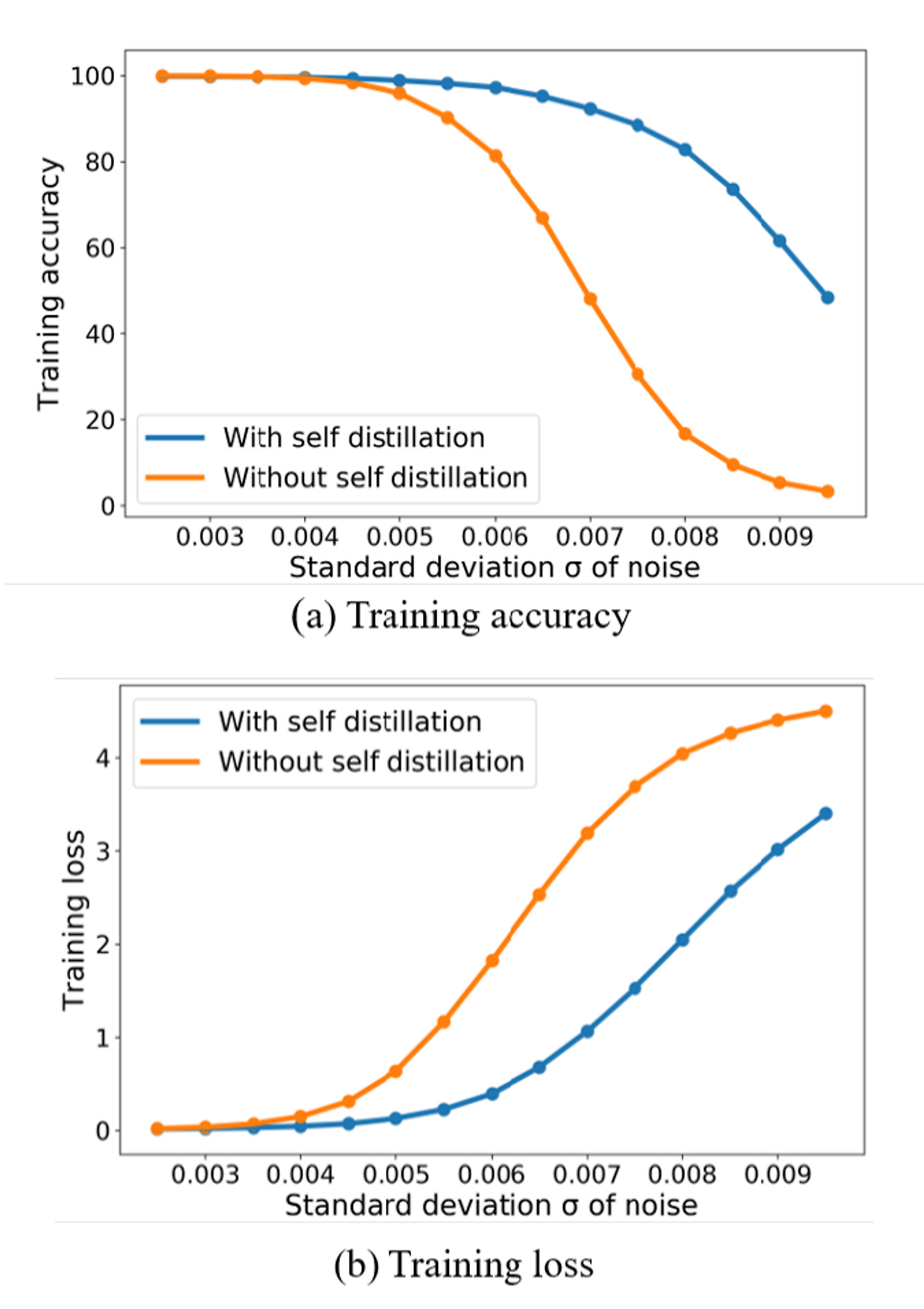
바로 parameter에 gaussian noise를 줘 가면서 accuracy와 loss를 측정해나갔다. (flat minima, sharp minima는 parameter space에서 일어나는 문제니까 이렇게 측정하는게 맞는 것 같다.)
5.2. Self distillation prevents model from vanishing gradient problem
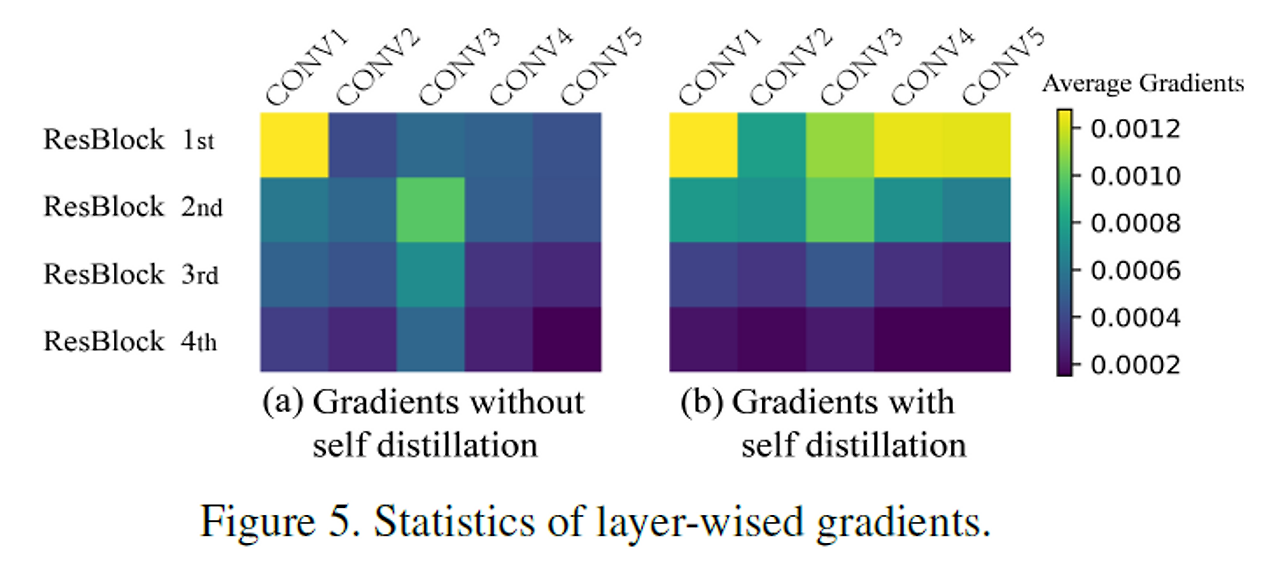
그 다음은 gradient vanishing 문제를 해결했다고 하는데, 이건 somehow obvious한게, Deep Supervised Network처럼 중간중간마다 gradient를 수급해주는 Classifier가 있고, 특히나, Deepest Classifier, label과도 연결되었기 때문에 더 smooth하게 학습이 가능할 것이다.
5.3. More discriminating features are extracted with deeper classifiers in self distillation

deeper classifier일수록 더 분류가 잘 되는 feature들을 뽑아내는 것을 알 수 있고, 이를 통해서 각 classifier마다의 discriminating principle에 대해서도 알 수 있다.
5.4. Future Works
- loss에서 소개되었던 두 hyper parameter, α,λ가 성능에 크게 영향을 미친다고 한다. 하지만, 이 부분에 대해서 충분히 조사하지 못했다고 한다
- self KD를 통해서 relatively flat minima에 converge하는 것은 밝혀냈지만, 이 flat minima가 과연 ideal flat minima인지는 밝혀냈다고 하지 못했다고 한다.
마치며..
이 글 역시 2023년도에 썼던 건데, 참 세상 많이 바뀌었다는 걸 느낀다.
self-distill이 살아남아 이래저래 적용이 되는 것 같다.
'AI' 카테고리의 다른 글
| [논문 읽기] Efficiently Identifying Task Groupings for Multi-Task Learning (0) | 2025.02.02 |
|---|